Abstract
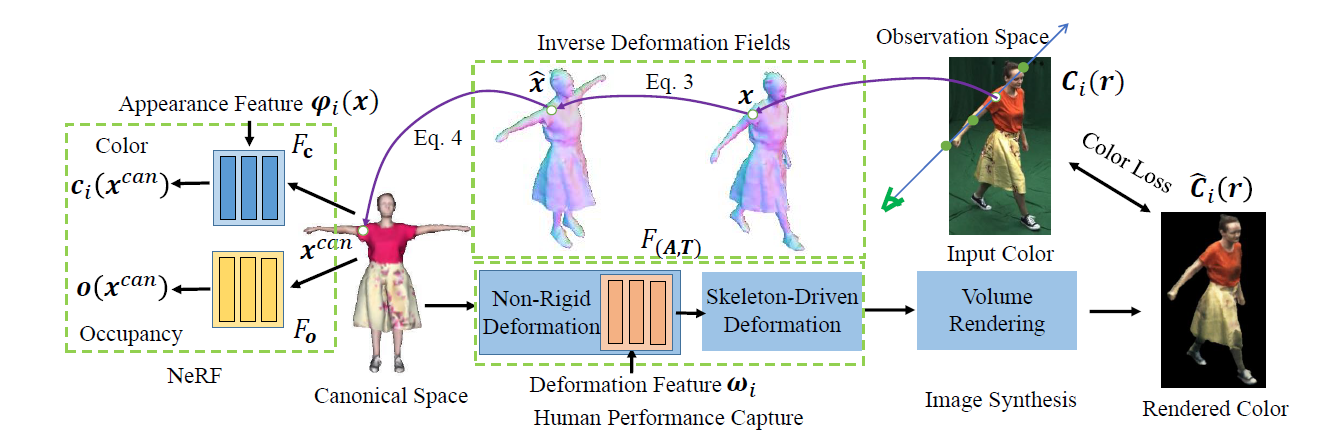
This paper addresses the challenge of human performance capture from sparse multi-view or monocular videos. Given a template mesh of the performer, previous methods capture the human motion by non-rigidly registering the template mesh to images with 2D silhouettes or dense photometric alignment. However, the detailed surface deformation cannot be recovered from the silhouettes, while the photometric alignment suffers from instability caused by appearance variation in the videos. To solve these problems, we propose NerfCap, a novel performance capture method based on the dynamic neural radiance field (NeRF) representation of the performer. Specifically, a canonical NeRF is initialized from the template geometry and registered to the video frames by optimizing the deformation field and the appearance model of the canonical NeRF. To capture both large body motion and detailed surface deformation, NerfCap combines linear blend skinning with embedded graph deformation. In contrast to the mesh-based methods that suffer from fixed topology and texture, NerfCap is able to flexibly capture complex geometry and appearance variation across the videos, and synthesize more photo-realistic images. In addition, NerfCap can be pre-trained end to end in a self-supervised manner by matching the synthesized videos with the input videos. Experimental results on various datasets show that NerfCap outperforms prior works in terms of both surface reconstruction accuracy and novel-view synthesis quality.
